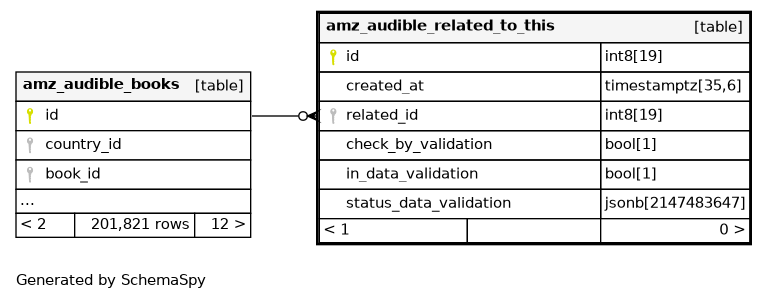
Columns
| Column | Type | Size | Nulls | Auto | Default | Children | Parents | Comments | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| id | int8 | 19 | √ | null |
|
|
|||||
| created_at | timestamptz | 35,6 | null |
|
|
||||||
| int8 | 19 | null |
|
|
|||||||
| check_by_validation | bool | 1 | null |
|
|
||||||
| in_data_validation | bool | 1 | null |
|
|
||||||
| status_data_validation | jsonb | 2147483647 | √ | null |
|
|
Indexes
| Constraint Name | Type | Sort | Column(s) |
|---|---|---|---|
| amz_audible_related_to_this_pkey | Primary key | Asc | id |
| amz_audible_related_to_this_related_id_09682afd | Performance | Asc | related_id |
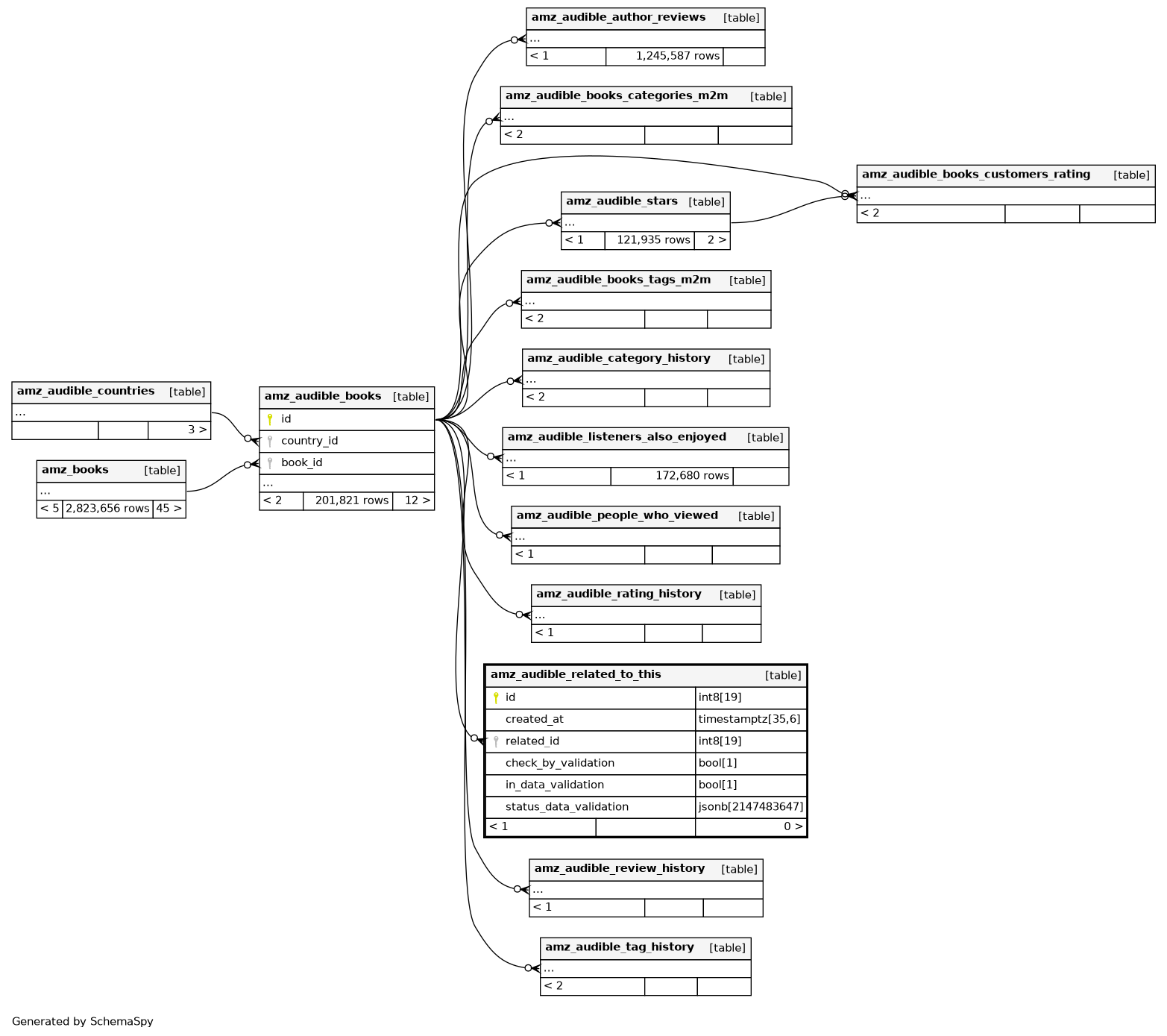
Relationships
Close relationships within degrees of separation